Era of Artificial Intelligence > home

By
Nicholas Hindley BSc(Hons), BA
PhD Student, ACRF Image X Institute

Background
Earlier this year, the Australasian College of Physical Scientists and Engineers in Medicine held its inaugural Machine Learning Workshop. This event, led by Dr Yu Sun, outlined the landscape of artificial intelligence in medical physics and radiation oncology. Having had the privilege to serve as an invited speaker, I was fortunate enough to see how AI is being used at the cutting-edge of medical imaging and radiotherapy. This article will attempt to draw out the key lessons from my talk on unsupervised learning.
Motivation
Unsupervised learning offers an important set of tools in artificial intelligence because:
- it allows us to better understand and visualise complex, multi-dimensional datasets.
- it thrives in situations where we cannot trust the ways our data have been labelled or the labels we’d like don’t exist.
- it paves the road to extending beyond the bounds of human performance by detecting nuances that are imperceptible to us.
Supervised vs unsupervised learning
Now, the easiest way to get a grip on unsupervised learning is to contrast it with its better-known counterpart: supervised learning. Supervised learning or learning with labels describes those situations in which we have various input data points and various output data points and we’d like a function which maps between them. This is the kind of thing we’ve all done in performing statistical regression. For instance, if we are supplied with a range of patient characteristics (age, height, weight, gender, years spent smoking, heart rate, etc) and we’d like to predict their risk of developing lung cancer then this falls squarely into the category of supervised learning.

In contrast, unsupervised learning or learning without labels describes those situations in which we have some input data that we’d like to better understand. For instance, if we take the same range of patient characteristics, a typical unsupervised learning algorithm could help us determine whether there are certain natural groupings within the dataset – this is called clustering.
To take a fairly trivial example, one might find that the subset of patients under the age of 18 tends to cluster with the subset of patients of shorter stature. This merely recapitulates the statistical observation that children and adolescents tend to be shorter than adults. Of course, this is a “hidden pattern” that we might have guessed even prior to gathering the data, but it is in noticing the more counter-intuitive groupings that unsupervised learning comes to the fore.

Two simple steps
Despite the myriad of unsupervised learning techniques, they can all be understood as proceeding via two steps:
- Quantify certain key relationships.
- Recast the data to better reflect these relationships.
Indeed, learning without labels can be seen as an exercise in reconceptualising data. When we collect data, the information we include is often motivated by some scientific understanding of the problem. In the example above, we included years spent smoking as a variable in modelling lung cancer incidence because there is strong evidence to suggest an association between the two.
However, we also included things like age, height and gender – and while these may also have some bearing on lung cancer incidence their effect is likely less strong.
Variables such as age, height and gender are often included simply because they are easy to collect. However, including additional variables can make our datasets unduly complicated, large and difficult to visualise.
This is where reconceptualising the data comes in handy! The key idea is that we need only consider those factors (or combinations of factors) that have some strong bearing on the variable of interest.

The flavours of unsupervised learning
In unsupervised learning, deciding which variables to privilege and which to discard depends on the kinds of relationships we ask our algorithm to find. Indeed, one way of categorising this set of techniques is by virtue of the metrics they use.
In perhaps the most widely used technique in unsupervised learning, principal components analysis (PCA), covariance is used to quantify strength of linear relationships between variables.
Critically, this gives us a measure of redundancy. If x is linearly related to y, the information contained in x is sufficient to recovery. So why include both? Given the widespread use of PCA, the underlying intuitions will be detailed in a later post.

Switching out covariance as our metric we get the other flavours of unsupervised learning. For instance, in k-means clustering we begin by randomly selecting k points within the input dataset. We call these points cluster centroids. We then measure the distance (or difference in values) between these centroids and their nearest neighbours.
From here, we iteratively vary the position of the centroids until this cumulative distance is minimised. The idea is that, at the final iteration, each centroid represents the canonical example of its neighbours. That is, we are left with k sets that partition the data into natural groupings.

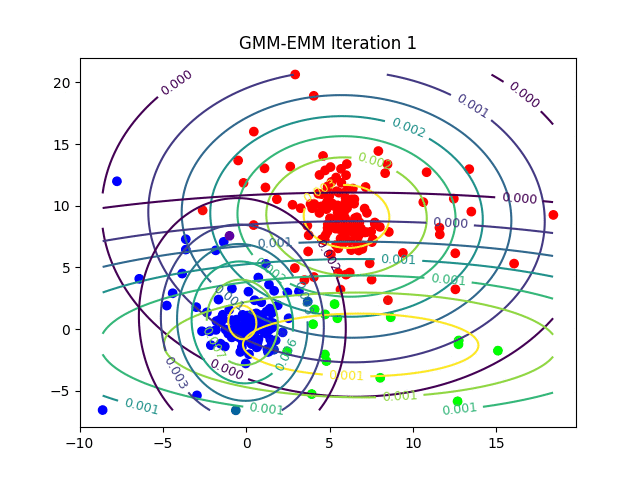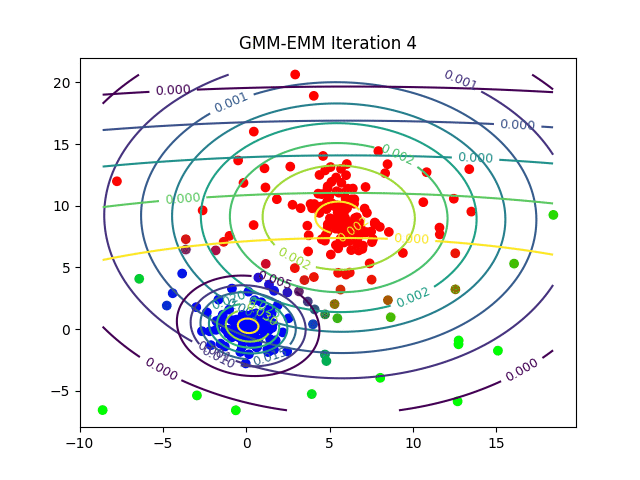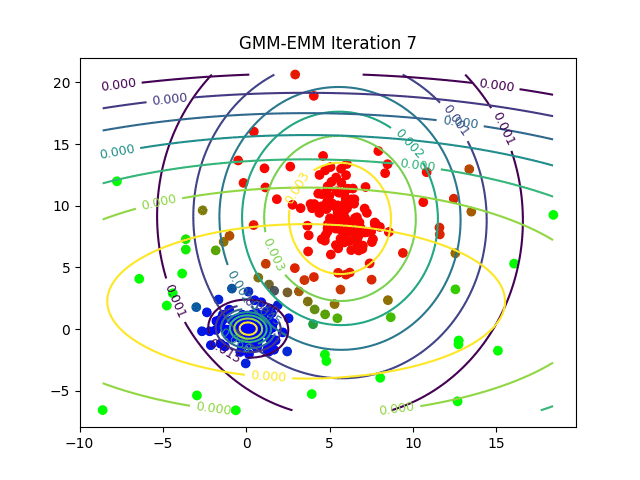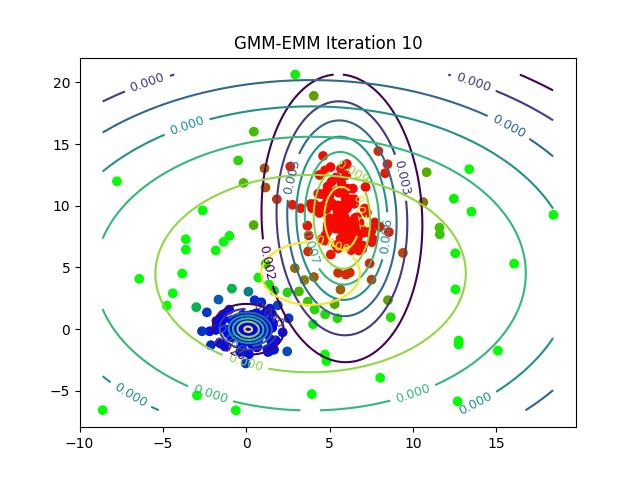
As a final example, instead of randomly assigning points within the input dataset, we can randomly assign Gaussian distributions. This yields a technique known as Gaussian mixture modelling. Here our metric is likelihood. In particular, for each input data point we determine the likelihood that it belongs to its nearest Gaussian distribution.
Each distribution is then iteratively varied by changing its mean and standard deviation until the cumulative likelihoods over all points is maximised and we arrive at a set of canonical distributions which can be used to categorise each individual point. So whether we are using PCA, k-means, Gaussian mixture models or some other technique, the key intuition behind unsupervised learning is to recast our data in a way which reflects the associations we care about.

For an animated version, click on:
{kind=link}
Limitations
Once we have understood a machine learning technique, it can become tempting to view it as a panacea rather than a specific tool to be used in specific circumstances. Therefore, having become acquainted with the core of unsupervised learning, we will now focus on its limitations.
First, “unsupervised learning” requires a great deal of supervision. There is a long (and growing) list of unsupervised learning techniques, and choosing one to settle on will require some fairly detailed knowledge of both the dataset at hand and of the learning algorithm itself. Lucky for us, we have seen that these learning algorithms can be categorised based on the relationships they seek to quantify and the ways in which they recast the original data – but getting the right pairing will certainly take some thought.
Second, the power of any model-based approach is limited by its weakest piece of data. Learning without labels is a double-edged sword. On the one hand, our algorithm may be able to detect certain nuances in the data that would have evaded us had we labelled the data ourselves. On the other hand, the algorithm does not get the benefit of being “coached” by what we believe to be true. Indeed, without human guidance, the algorithm is left to fend for itself and when given faulty data, it will learn faulty models. Therefore, the quality of your dataset becomes paramount in training unsupervised learning algorithms.
Lastly, machine learning provides insights which often require some work to interpret. This is a general point which extends beyond unsupervised learning. But it becomes crucial where we ask algorithms to sort signal from noise for us. For example, in PCA we recast original dataset using these special discrete elements known as principal components. However, understanding what these components signify beyond mere mathematical abstraction requires a deep understanding of the dataset, the physical or biological processes at work and the inner workings of the learning algorithm itself.

Aids for discovery
Despite the initial appeal of algorithms that learn without the need for human intervention, the way forward is to couple the deep insights you have developed in your particular field with this rapidly advancing set of mathematical tools. That is, in this nascent stage in machine learning, the aim should be to work hand-in-hand with these clever learning algorithms before we take the training wheels off altogether. Indeed, there is much to be gained in viewing these powerful techniques as aids for discovery rather than mindless assembly line workers.
Nicholas Hindley, 6 September 2019